Di Corrado Pandiani, pubblicato su Linux&C. n° 59.
Ottimizzare MySQL: come rendere più veloci le query SQL
L’obiettivo minimo che gli sviluppatori che utilizzano MySQL per le proprie applicazioni raggiungono con una certa dimestichezza è quello di saper scrivere query SQL per ottenere i risultati desiderati. In molti, però, si fermano a questo livello, rinunciando a sondare gli strani misteri che sono patrimonio di un buon database administrator: capita quindi che, al crescere della dimensione dei dati e della complessità delle interrogazioni da implementare, ci si trovi di fronte a problemi apparentemente irrisolvibili o ad applicazioni con tempi di risposta inaccettabili.
Non sempre la determinazione del collo di bottiglia è cosa immediata: spesso è decisamente più facile pensare all’acquisto di hardware più potente, o alla ricerca del parametro di configurazione che, se ben impostato, potrebbe consentire la risoluzione di ogni problema.
Il più delle volte le soluzioni da mettere in pratica non sono queste, o meglio, non lo sono in prima istanza: quello che va fatto è una analisi dello schema del database e delle query eseguite dal server.
Riscrivere qualche interrogazione, ottimizzandola, e sistemare qualche tabella è spesso – non sempre – il solo intervento necessario, e in pochi minuti si può addirittura sbloccare una situazione che sembrava ormai cronica.
MySQL è notoriamente un DBMS molto performante, ma non ci si può fidare alla cieca di questa (pur vera) certezza: una progettazione errata e, soprattutto, query scritte male (spesso conseguenza di un database non normalizzato), sono in grado di affossare le performance di qualsiasi server, è solo questione di tempo, dati e memoria.
MySQL mette a disposizione uno strumento prezioso di analisi, poco conosciuto dai non addetti ai lavori, la funzione EXPLAIN, che sarà l’argomento di questo articolo: ne analizzeremo il funzionamento e, con qualche esempio, vedremo quale sia la metodologia di analisi per ottimizzare il funzionamento delle query.
Questa conoscenza consentirà di restituire un po’ di cicli macchina al vostro server “impallato” e, molto probabilmente, di scongiurare nell’immediato l’acquisto di nuovo hardware, cosa che il vostro capo o il vostro cliente apprezzerà più di ogni altro aspetto della questione.
Ripassiamo gli indici
Gli indici saranno i principali protagonisti della nostra trattazione.
Un indice associato ad una tabella non è troppo diverso da quello che trovate all’inizio di un libro: senza di esso, rintracciare un paragrafo o un capitolo diventa assai difficile e c’è da scorrere tutte le pagine presenti. Se poi c’è da trovare tutte le occorrenze di una certa parola, la situazione diventa ancora più tragica in assenza di un indice analitico.
MySQL utilizza la stessa tecnica vista per il libro: se una tabella non ha indici associati, l’unico modo per ritrovare i record di interesse è eseguire l’operazione che prende il nome di “full table scan”, una lettura riga per riga di tutte le informazioni presenti.
Pensate cosa significhi in termine di I/O effettuare una lettura completa di svariati gigabyte solo per trovare qualche riga che soddisfi una ricerca.
Gli indici sono strutture che “puntano” alle informazioni presenti nella tabella, come una sorta di segnalibri: sono composti da una sequenza di nodi contenenti i riferimenti ai record e vengono utilizzati per velocizzare le ricerche all’interno della tabella stessa, laddove questo sia possibile; sono costruiti sui valori di una o più colonne, e creano corrispondenze tra certi valori delle colonne e le righe dove tali valori si trovano.
Nella metafora vista in precedenza, un nodo dell’indice conterrà il titolo di un capitolo o del paragrafo, e verrà tenuto il riferimento del numero di pagina ove tale informazione si trova.
In MySQL è possibile creare diversi tipi di indice:
- PRIMARY KEY: è l’indice associato alla chiave primaria, non può contenere valori NULL né valori duplicati. Usato spesso in associazione con la direttiva auto_increment in caso di valori numerici unici.
- UNIQUE: non ci possono essere valori duplicati, sono consentiti i valori NULL.
- INDEX: ci possono essere valori duplicati e valori NULL.
- FULLTEXT: indice specializzato per la ricerca di parole nei testi.
Oltre ad essere strutture generalmente molto più piccole rispetto alla tabella cui fanno riferimento, gli indici hanno un trattamento di riguardo da parte di MySQL: i nodi, comprensivi di valore e puntatore, vengono conservati in un buffer di memoria denominato key_buffer (qua e nel seguito si fa riferimento all’engine MyISAM), che contiene i nodi utilizzati più di recente e, compatibilmente con la memoria disponibile, può anche contenere tutti gli indici del database.
La sua dimensione è data dalla variabile key_buffer_size, impostabile a piacere nella sezione [mysqld] del file my.cnf, il file di configurazione di MySQL che si trova in /etc (o in /etc/mysql a seconda della distribuzione).
Il key_buffer è preferibile che abbia il valore più elevato possibile, più è grande maggiore è la probabilità che il nodo dell’indice richiesto sia già in memoria, compatibilmente però con la RAM a disposizione, cercando di evitare il pericolo di swap del sistema operativo che farebbe degradare le performance.
Le query SQL con condizioni di ricerca espresse su campi indicizzati possono trarre grandi vantaggi in termini di tempo di esecuzione: ci sarebbe ancora da dire molto sulla gestione degli indici da parte del database, ma per i nostri scopi può bastare.
Identificare le query da ottimizzare
Prima di usare EXPLAIN dobbiamo selezionare le query che devono essere oggetto della nostra analisi ma, fortunatamente, non tutte avranno bisogno di essere ottimizzate e potranno tranquillamente essere considerate trascurabili.
Per questo scopo ci serve il contenuto dello slow-log, un file di testo nel quale MySQL scrive tutte le query che vengono eseguite in un tempo superiore al valore impostato nel parametro long_query_time (che di default vale 10 secondi).
Associate ad ogni query vengono inoltre riportate informazioni di fondamentale importanza: data e ora, tempo di esecuzione espresso in secondi, numero di righe, tempo di lock, utente richiedente.
Non essendo lo slow-log attivo per default, dobbiamo abilitarlo inserendo il parametro log-slow-queries[=file_name] nella sezione [mysqld] del file my.cnf: in assenza della parte file_name, che ne può specificare un path e un nome alternativo, il file verrà creato nella directory dei dati e si chiamerà host_name-slow.log. Se non sappiamo quale sia la directory dei dati possiamo scoprirlo con il comando:
mysql> SHOW VARIABLES LIKE 'datadir';
Impostati i parametri in my.cnf sarà necessario il riavvio del server. Il database dovrà lavorare per un po’ di tempo affinché il file di log venga popolato. Per disporre di un contenuto significativo che dia una visione realistica del funzionamento del server occorre che lo slow-log copra diverse ore o, meglio ancora, diversi giorni: per una corretta selezione delle query candidate all’ottimizzazione è bene valutare il funzionamento del database su un arco temporale che copra tutte le variazioni possibili di carico e annoveri il funzionamento di tutte le applicazioni che ne fanno uso, in quanto uno slow-log parziale può portare ad analisi non complete e fuorvianti.
Dall’analisi delle query presente possiamo costruire una lista di interrogazioni da analizzare partendo dalle più lente e più frequenti, facendo molta attenzione però agli eventuali falsi positivi, le query cioè che sono presenti nel log pur non essendo scritte male o lente per loro natura.
Attenzione anche a tutti gli elementi esterni al database possono influenzare le perfomance e che possono rendere “lente” query che, in situazioni normali, non lo sarebbero state: un caso tipico è quello di un applicativo esterno che ha fatto un uso anomalo delle risorse di sistema (tempo macchina o disco) sottraendole agli altri processi, tra cui anche MySQL.
Altro caso assai frequente riguarda le query eseguite durante il backup del database: nel tempo necessario ad eseguire la copia dei dati è probabile che si generino delle slow query conseguente all’intenso I/O.
Altre query da escludere sono quelle poco frequenti, quelle eseguite per errore e quelle eseguite da un amministratore per onerose operazioni di modifica alle tabelle o complesse ricerche. E’ comunque necessario fare uso di un po’ di buon senso: se è vero che in termini generali tali query possono essere trascurate, è altrettanto vero che se una certa query eseguita una volta ogni giorno impiega un’ora non può essere tralasciata, soprattutto se in tale lasso di tempo tiene bloccate risorse (tabelle) per i thread concorrenti.
Se sul server è attiva l’opzione log_queries_not_using_indexes lo slow-log conterrà anche tutte le query che non hanno fatto uso di alcun indice, indipendentemente dalla velocità di esecuzione: questo può essere utile per individuare molte query eseguite in un tempo relativamente basso ma che comunque sarebbero migliorabili.
Se lo slow-log è di piccole dimensioni può essere controllato manualmente, ma nella maggior parte dei casi è sicuramente più comodo l’utilizzo di un programma presente in tutte le installazioni di MySQL, mysqldumpslow, che esegue l’analisi dello slow-log, producendo in output un documento di sintesi in cui le query simili sono raggruppate in base al tempo medio di esecuzione e la frequenza, ordinate a partire dalla più lenta. I parametri numerici e testuali presenti nelle query sono rispettivamente sostituiti con i simboli generici N ed S.
I file di log non sono consultabili da tutti gli utenti e, a seconda delle distribuzioni e della tipologia di installazione, è probabile che ad essi abbia accesso solo l’utente di root oppure l’utente con cui MySQL è in esecuzione (e il gruppo relativo), e questo comporta l’impossibilità dell’analisi in diverse situazioni: il caso più tipico è chi utilizza un database su una piattaforma in hosting, senza avere accesso fisicamente alla shell e alle impostazioni del server.
In tali circostanze o si riesce a replicare localmente l’intera installazione effettuando una analisi in ambiente di pre-produzione (che dovrebbe essere sempre presente, non solo per i test prestazionali), o si è costretti ad eseguire sull’applicazione la misura delle performance, magari scrivendo il tempo impiegato in un file di log che può essere consultato offline.
La funzione EXPLAIN
EXPLAIN viene utilizzata per consultare il “query optimizer”, la sezione del server che effettua le valutazioni su come rendere più veloce l’interrogazione che viene richiesta al database: è questa sezione che decide se un indice dovrà essere utilizzato, l’ordine di verifica delle condizioni ecc.
In pratica, interrogando il query optimizer si chiede a MySQL come intende sviluppare la query.
Le informazioni che fornisce EXPLAIN sono utili per molti aspetti:
- forniscono indizi circa l’opportunità di aggiunta di alcuni indici alle tabelle;
- se una tabella ha già degli indici utilizzati, l’output del comando aiuta a capire come vengono utilizzati dal motore;
- se gli indici esistono ma non vengono utilizzati dal query optimizer, aiuta a scrivere meglio il codice SQL affinché la query venga eseguita beneficiando della presenza dell’indice.
L’uso di EXPLAIN è di estrema importanza per studiare i join che, se male utilizzati, hanno lo svantaggio di poter incrementare a dismisura il carico di lavoro richiesto al server: infatti, se una query che interroga una tabella di 1000 righe è scritta male, nel caso peggiore il server dovrà leggere al massimo 1000 righe; se invece viene effettuato un join di due tabelle di 1000 righe ciascuna, il caso peggiore comporta l’esame di tutte le possibili combinazioni del prodotto cartesiano tra le due tabelle, ossia 1.000.000 di righe!
EXPLAIN può aiutare a riscrivere meglio le query o modificare le tabelle in modo tale che il server risolva il join nel modo meno oneroso possibile, riducendo il numero di combinazioni da esaminare.
EXPLAIN produce una riga di output per ogni tabella referenziata dalla query. L’ordine di visualizzazione delle righe è importante: indica la sequenza che MySQL utilizzerà per considerare le tabelle nella risoluzione dei vincoli di join, indipendentemente da come sono scritte nella parte FROM.
EXPLAIN consente di analizzare qualsiasi query SELECT, ma può essere utilizzato indirettamente anche per UPDATE e DELETE scrivendo una generica SELECT * con le stesse condizioni di FROM e WHERE: solitamente le condizioni usate nelle query di modifica dei dati sono meno complesse di quelle usate in quelle di selezione, il che rende questa operazione non molto frequente.
Primo esempio: utilizzo corretto degli indici
Per il nostro primo esempio utilizziamo il database Sakila di una ipotetica videoteca, liberamente scaricabile da
http://downloads.mysql.com/docs/sakila-db.tar.gz
Delle 22 tabelle presenti ne useremo per i nostri esempi solo 3.
- film: elenco dei film a catalogo comprensivi di titolo, genere, durata a altre informazioni
- actor: elenco di attori (nomi di fantasia)
- film_actor: tabella che di collegamento tra gli attori e i film in cui hanno recitato
Le tabelle sono già ottimizzate a dovere, ma per capire il funzionamento è necessario crearne di nuove non ottimizzate, senza indici:
mysql> CREATE TABLE lista_attori SELECT * FROM actor;
mysql> CREATE TABLE lista_film SELECT * FROM film;
mysql> CREATE TABLE lista_film_attori
SELECT * FROM film_actor;
L’esecuzione di CREATE TABLE … SELECT … consente infatti di copiare tutti i dati di una tabella in una nuova ricreando gli stessi campi ma senza indici.
Eseguiamo una query per trovare i nomi degli attori e i titoli dei film in cui hanno recitato la cui durata è maggiore di tre ore.
mysql> SELECT first_name, last_name, title
-> FROM lista_film, lista_attori, lista_film_attori
-> WHERE lista_film.film_id=lista_film_attori.film_id
-> AND lista_attori.actor_id=lista_film_attori.actor_id
-> AND length > 180;
La stessa query si può scrivere con la sintassi JOIN estesa, in maniera del tutto equivalente anche in termini di performance:
SELECT first_name, last_name, title
FROM
lista_film
INNER JOIN lista_film_attori ON
lista_film.film_id=lista_film_attori.film_id
INNER JOIN lista_attori ON
lista_attori.actor_id=lista_film_attori.actor_id
WHERE
length > 180;
Osserviamo il risultato che restituisce:
| first_name | last_name | title |
| PENELOPE | GUINESS | KING EVOLUTION |
| ED | CHASE | YOUNG LANGUAGE |
...
| MATTHEW | CARREY | WORST BANGER |
200 rows in set (29.02 sec)

Notate come il tempo di esecuzione sia particolarmente alto. La velocità di esecuzione dipende anche dalla potenza di calcolo del computer, quindi potreste ottenere un risultato un po’ diverso, ma probabilmente dello stesso ordine di grandezza. Vediamo allora come migliorare la situazione.
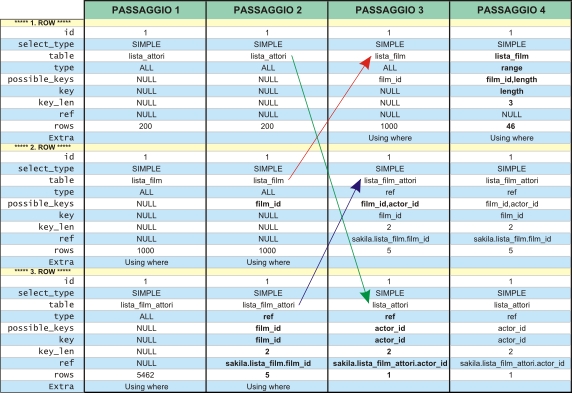
Proviamo a fare un EXPLAIN della query appena eseguita, il cui output è presente in figura 2 nel primo passaggio:
mysql> EXPLAIN SELECT first_name, last_name, title
-> FROM lista_film, lista_attori, lista_film_attori
-> WERE lista_film.film_id=lista_film_attori.film_id
-> AND lista_attori.actor_id=lista_film_attori.actor_id
-> AND length > 180;
Notiamo anzitutto che i campi type hanno il valore ALL per tutte le tabelle. Ciò significa che per ognuna viene fatto un full scan per ogni combinazione di righe dalle tabelle precedenti. Per conoscere il numero di combinazioni totali è sufficiente moltiplicare tra loro i valori riportati in rows.
mysql> select 200*1000*5462 as prodotto_cartesiano;
| prodotto_cartesiano |
| 1092400000 |
MySQL deve costruirsi oltre 1 miliardo di possibili combinazioni, controllarle una per una per individuare alla fine le 200 righe del risultato che cerchiamo: ecco spiegata la ragione della estrema lentezza della query.
Effettuiamo una prima ottimizzazione creando due indici per consentire di risolvere più facilmente la prima condizioni di join presente nella query (notate come la forma estesa semplifichi la lettura alla ricerca delle necessità di ottimizzazione):
mysql> ALTER TABLE lista_film ADD INDEX(film_id);
Query OK, 1000 rows affected (0.07 sec)
Records: 1000 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE lista_film_attori ADD INDEX(film_id);
Query OK, 5462 rows affected (0.01 sec)
Records: 5462 Duplicates: 0 Warnings: 0
Eseguiamo nuovamente EXPLAIN, il cui output è presente sempre in figura 2 ma nel secondo passaggio.
Notiamo che la situazione è considerevolmente migliorata per la tabella lista_film_attori per la quale è possibile utilizzare l’indice costruito su film_id come ci dice il campo key. Per ogni combinazione di righe dalle tabelle precedenti la tabella in questione mette in gioco 5 righe (rows) e risolve il join con lista_film usando la colonna film_id (ref).
mysql> select 200*1000*5 as prodotto_cartesiano;
| prodotto_cartesiano |
| 1000000 |
Abbiamo ridotto il numero delle combinazioni di tre ordini di grandezza, da oltre un miliardo a un milione. La query eseguita dopo questa prima ottimizzazione impiega oltre un decimo del tempo. Proseguiamo con l’ottimizzazione creando gli indici per agevolare l’altra condizione di join.
mysql> ALTER TABLE lista_attori ADD INDEX(actor_id);
Query OK, 200 rows affected (0.00 sec)
Records: 200 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE lista_film_attori ADD INDEX(actor_id);
Query OK, 5462 rows affected (0.02 sec)
Records: 5462 Duplicates: 0 Warnings: 0
Nel terzo passaggio vediamo come è ulteriormente variato l’output di EXPLAIN.
Siamo ora in una situazione già accettabile: le combinazioni sono scese a 5000 (1000*5*1) con due tabelle su tre in grado di sfruttare un indice.
Notiamo anche che l’ordine delle tabelle è variato e quanto mostrato da EXPLAIN è l’esatta sequenza con cui “query optimizer” aprirà le tabelle e risolverà i join. L’ordine scritto nel FROM non ha alcuna rilevanza: la scelta della sequenza più opportuna è operata in base a quella che è in grado di fornire il risultato migliore.
In questo caso vi è la necessità di effettuare il full scan di lista_film, e viene eseguito come prima operazione per evitare di doverlo ripetere più volte se fosse posticipato nella esecuzione della query, ragion per cui lista_film è la prima tabella considerata.
La necessità di effettuare il full scan è data dalla presenza della condizione sul campo length (length > 180) che non è un campo indicizzato. Proviamo allora a definire un indice anche per esso e vediamo cosa succede.
mysql> ALTER TABLE lista_film ADD INDEX(length);
Query OK, 1000 rows affected (0.02 sec)
Records: 1000 Duplicates: 0 Warnings: 0
L’output della nuova EXPLAIN è indicato come quarto passaggio. Ora anche la prima tabella può sfruttare l’indice e il valore range del campo ref indica che solo un certo intervallo dell’indice viene letto, non tutto.
Calcoliamo la complessità finale della query:
mysql> select 46*5*1 as prodotto_cartesiano;
| prodotto_cartesiano |
| 230 |
Ora eseguiamola nuovamente dopo le ottimizzazioni:
mysql> SELECT first_name, last_name, title
-> FROM lista_film, lista_attori, lista_film_attori
-> WHERE lista_film.film_id=lista_film_attori.film_id
-> AND lista_attori.actor_id=lista_film_attori.actor_id
-> AND length > 180;
| first_name | last_name | title |
| PENELOPE | GUINESS | KING EVOLUTION |
| ED | CHASE | YOUNG LANGUAGE |
...
| MATTHEW | CARREY | WORST BANGER |
200 rows in set (00.01 sec)
Il tempo di esecuzione si è decisamente ridotto!
Un nuovo esempio: riscrivere una query
Supponiamo che siano state inserite delle durate errate nel campo length della tabella film, e il valore corretto sarebbe il 10% in più rispetto ai valori presenti nel database.
Prima di modificare il campo, però, cerchiamo quali sarebbero i film la cui durata sarà superiore alle 3 ore (180 minuti).
Creiamo un indice sul campo length e analizziamo una semplice query:
mysql> ALTER TABLE film ADD INDEX(length);
Query OK, 1000 rows affected (0.14 sec)
Records: 1000 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT title FROM film
WHERE 1.1*length > 180\G
********************* 1. row *********************
id: 1
select_type: SIMPLE
table: film
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 927
Extra: Using where
C’è da chiedersi perché non venga utilizzato l’indice definito sulla colonna length. La spiegazione è oltremodo semplice: quando una condizione è espressa in termini di una funzione o di una operazione algebrica applicata ad un campo indicizzato, MySQL non può sfruttare l’indice in quanto non conosce a priori il valore assunto dall’espressione o dalla funzione. Il valore deve quindi essere calcolato riga per riga, obbligando un full scan della tabella, come EXPLAIN correttamente indica.
mysql> EXPLAIN SELECT title FROM film
WHERE length > 180/1.1\G
********************* 1. row *********************
id: 1
select_type: SIMPLE
table: film
type: range
possible_keys: length,length_2
key: length
key_len: 3
ref: NULL
rows: 155
Extra: Using where
Provando a scrivere la query con una condizione espressa in un modo diverso ma equivalente, si verifica come l’indice venga correttamente utilizzato.
Forzare l’ordine delle tabelle
Nella maggior parte dei casi le scelte effettuare dal query optimizer per quanto riguarda l’ordine di lettura delle tabelle sono quelle ottimali, ma può però capitare che non lo siano e si voglia costringere MySQL ad operare una scelta diversa: è quindi sufficiente aggiungere alla prima SELECT il modificatore STRAIGHT_JOIN, che farà in modo che l’ordine considerato sarà quello specificato in FROM.
Fortunatamente non capiterà spesso di andare contro le scelte di MySQL, ma come esercizio si può provare a forzare l’ordine delle tabelle per verificare come cambino le performance di una query.
Aggiornare le statistiche
Abbiamo citato il fatto che il valore di rows sia una stima calcolata in base alle statistiche sulla distribuzione degli indici e non il numero reale delle righe selezionate. Non è scopo di questo articolo spiegare gli internal di questa valutazione, ma ciò chi ci preme sottolineare è che i valori utilizzati per le ottimizzazioni devono essere il più aggiornati possibile: è quindi consigliabile eseguire di tanto in tanto il comando
mysql> ANALYZE TABLE nome_tabella;
che ha il compito specifico di effettuare un refresh delle informazioni necessarie.
Non esiste una regola per decidere la frequenza dell’esecuzione, molto dipende dalla quantità di modifiche dei campi indicizzati. Per sicurezza è utile eseguirlo su tutte le tabelle con cadenza giornaliera o settimanale a seconda dei casi (basta affidarsi a cron) e comunque eseguirlo sistematicamente tutte le volte che si fanno modifiche di massa di valori associati ad indice, o dopo aver cancellato grosse parti di una tabella. Anche il comando che segue può servire allo scopo:
mysql> OPTIMIZE TABLE nome_tabella;
Anche OPTIMIZE TABLE aggiorna le statistiche di distribuzione degli indici, ma in più esegue altre operazioni (ad esempio compattare le tabelle per recuperare lo spazio vuoto) e potrebbe risultare più lento.
Conclusioni
Vi abbiamo mostrato come identificare le query più lente sfruttando lo slow-log: in seguito l’uso di EXPLAIN ha mostrato come si possano analizzare tali query al fine di creare gli indici necessari per ridurre il numero di combinazioni di righe e, nel caso in cui tali indici non venissero utilizzati, modificare la struttura della query per permettere a MySQL una migliore ottimizzazione della interrogazione.
Tutto ciò a vantaggio dei tempi di risposta e del fatto che avrete un DBMS in grado di poter assolvere a nuovi compiti.
A volte purtroppo capita anche il caso in cui, nonostante tutte le possibili ottimizzazioni, il sistema risulti ancora troppo lento. Solo in tal caso non resta altro da fare che potenziare l’hardware o pensare a soluzioni basate sulla replicazione o MySQL Cluster a seconda dei casi, ma qua il discorso diventa sicuramente più complesso e sarà oggetto di ulteriori articoli nei prossimi numeri.
Riquadro 1: I campi di una EXPLAIN SELECT
id: valore numerico progressivo che indica la SELECT a cui si fa riferimento; se non sono presenti query annidate o UNION varrà sempre 1.
select_type: categorizza il tipo di SELECT; se non si hanno query annidate o UNION varrà sempre SIMPLE.
table: è il nome della tabella cui le informazioni della riga fanno riferimento.
type: indica il tipo di join. Il suo valore è una misura dell’efficienza con cui MySQL risolve una condizione di join (vedi riquadro 2 per tutti i possibili valori).
possible_keys: indica quali sono gli indici della tabella che MySQL può considerare per identificare la righe che soddisfano la query. Può essere una lista di uno o più valori, o può valere NULL se non ci sono indici o se nessuno degli indici può essere usato.
key: indica il nome dell’indice che “query optimizer” ha deciso di utilizzare. Se il valore è NULL vuol dire che nessun indice è stato usato; questo capita ovviamente se non vi sono indici oppure se optimizer ritiene che uno scan della tabella sia più veloce (tipico di quando il numero delle righe selezionate è relativamente grande rispetto al numero totale di righe della tabella)
key_len: indica quanti byte dell’indice sono usati. E’ un’informazione utile solo nei casi in cui vi sia un indice multiplo, costruito cioè con l’unione di più colonne. Per gli scopi dell’articolo non ci interessa approfondirlo ulteriormente.
ref: indica quali colonne della tabella precedente sono usate per risolvere la condizione di join con la tabella attuale. Vale NULL nel caso della prima tabella.
rows: è un valore numerico che rappresenta il numero di righe messe in gioco dalla tabella. Attenzione però, si tratta solo di una stima calcolata da optimizer in base alle statistiche interne sugli indici, non è il numero delle righe realmente selezionate. Per fortuna ciò che conta non è il valore puntuale ma l’ordine di grandezza di tale numero, che nella quasi totalità dei casi è attendibile. Il valore “vero” lo si può ottenere solo eseguendo la query, cosa che EXPLAIN non fa.
Extra: fornisce informazioni addizionali sul join (vedi riquadro 3 per tutti i possibili valori).
Riquadro 2: I valori del campo Type presente nella EXPLAIN
system: la tabella ha esattamente una riga.
const: la tabella ha una sola riga che soddisfa alle condizioni di join. E’ simile a system ma con la differenza che la tabella può avere molte altre righe.
eq_ref: è letta una sola riga dalla tabella corrente per ogni combinazione di righe dalle tabelle precedenti. Tipico dei join in cui MySQL può utilizzare una primary key per identificare le righe di una tabella.
ref: sono lette diverse righe per ogni combinazione di righe dalle tabelle precedenti. Simile a eq_ref, ma può capitare quando viene usato un indice multiplo o quando non viene utilizzato un indice per intero (solo la parte sinistra).
ref_or_null: simile a ref, ma in più MySQL deve cercare righe contenenti NULL.
range: l’indice è usato per selezionare le righe che cadono in un certo intervallo di valori. Tipico di quando vengono usate condizioni di disuguaglianza, ad esempio id<10.
index: MySQL esegue un full scan dell’indice. Non è un caso piacevole ma sempre meglio di un full scan della tabella. Un indice è più veloce da leggere dei dati reali in quanto è ordinato, solitamente più piccolo dei dati e spesso si trova per buona parte in memoria.
ALL: MySQL esegue un full scan della tabella da disco. E’ la situazione peggiore, soprattutto se si riferisce ad una tabella che non sia la prima: deve essere eseguito il full scan per ogni combinazione di righe dalle tabelle precedenti e le performance peggiorano esponenzialmente. Assolutamente da evitare, specialmente quando la dimensione delle tabelle non è trascurabile.
Riquadro 3: I valori del campo Extra presente nella EXPLAIN
Ecco i valori possibili del campo Extra: quelli con un + identificano valori “buoni”, quelli con – valori “cattivi”.
- +Using index: MySQL può ottimizzare la query leggendo i valori dall’indice senza dover leggere i corrispondenti dati dalla tabella fisica. Questa ottimizzazione è possibile quando ad esempio vengono selezionate solo colonne che sono indicizzate.
- +Where used: MySQL usa le condizioni espresse in WHERE per identificare le righe che soddisfano la query. Senza tali condizioni si sarebbero ottenute tutte le righe della tabella.
- +Distinct: MySQL legge una singola riga dalla tabella per ogni combinazione di righe dalle tabelle precedenti.
- +Not exists: MySQL riesce ad ottimizzare una condizione di LEFT JOIN non considerando alcune righe.
- -Using filesort: Le righe che soddisfano la query devono essere ordinate. E’ un passo ulteriore di computazione.
- -Using temporary: Deve essere creata una tabella temporanea per poter processare la query.
- -Range checked for each record: MySQL non può determinare in anticipo quale indice utilizzare. Per ogni combinazione di righe dalle tabelle precedenti controlla gli indici della tabella corrente per cercare il migliore da utilizzare. Non è una buona situazione, ma meglio che non usare gli indici del tutto.